
From the t-test to ANOVA
When I talk to instructors of introductory statistics about the topics they cover, I often hear something like the following: “ANOVA is in the book, but we usually don’t get to it.” And not having gotten to it, many instructors lack confidence that they understand ANOVA. So, even though this post is intended for instructors, it’s worthwhile to spend a little time discussing the motivation for ANOVA. Then I’ll move to the app itself, which is intended both as an ANOVA calculator and an introduction to the concept.
In the two-sample t-test, inference is done on the difference in means between the two groups. The inference can be displayed as a confidence interval which shows up as the black sideways H in the t-test little app. Since there are just two groups, there is (obviously!) only one difference between them, so we have to look at only one confidence interval.
What to do when there are three or more groups? With three groups – A, B, and C – there are three possible differences: A ➔ B, A ➔ C, and B ➔ C. This means that there will be three confidence intervals: one for each of the three differences. With four groups – A, B, C, and D – there are six differences. With five groups, there are 10 differences.
As always, the right approach depends on what it was that you are really looking to find out. Some possibilities:
- You knew before doing the analysis that you are interested in the difference, say A ➔ D. In this case you can do a straightforward two-sample t-test on the two groups of interest.
- You realized that you were interested in A ➔ D only after you looked at several or all of the groups. Now you are in a philosophical bind because you are doing a post hoc test.1 However much sense it might make in retrospect that you should have been looking at groups A and D, your inference needs to take into account what might have been. There are several ways that you might do this, for example a Bonferonni correction, or a Tukey range test. The problem here is not a small matter. It is one of the explanations for the so-called “statistical crisis in science”.
- Ask a different question in the framework of response and explanatory variables. Group membership is the explanatory variable. And so we ask: Is there reason to believe from the data that the response variable is connected to the explanatory variable?
Number (3) is what ANOVA is about.
ANOVA is usually introduced in the context of a difference in means between groups, and that’s what the t-test little app does. In fact, ANOVA is a much more general method that can be applied to multiple explanatory variables, be they categorical or quantitative. But we’ll stick for now to the so-called one-way ANOVA of comparing groups.
Orientation
When you open up the t-test little app, you’ll see something like this:
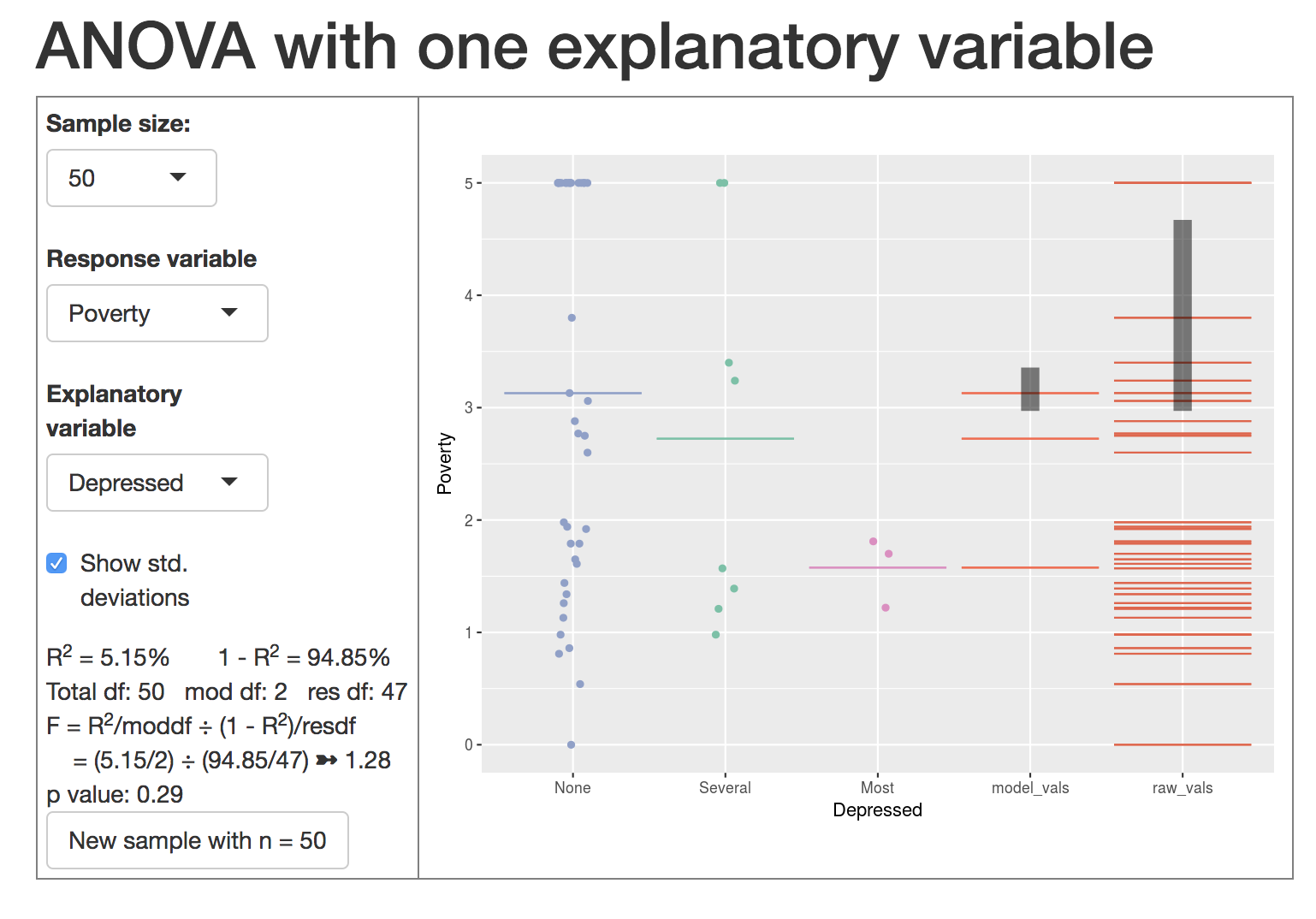 On the left are the familiar controls for setting the sample size and selecting a response and explanatory variable. The data are from
On the left are the familiar controls for setting the sample size and selecting a response and explanatory variable. The data are from NHANES as in many other little apps.
On the right is a data graph. This one shows Poverty vs Depressed.^[According to the codebook for NHANES:
- Poverty: A ratio of family income to poverty guidelines. Smaller numbers indicate more poverty.
- Depressed: Self-reported number of days where participant felt down, depressed or hopeless. Reported for participants aged 18 years or older. One of None, Several, Majority (more than half the days), or AlmostAll.]
The leftmost three categories on the Depressed-axis are as reported in the codebook: None, Several, Most. (Evidently in this sample there were no cases with level AlmostAll.) The graphic is a jitterplot, showing the value of Poverty for each of the 50 cases being displayed. The horizontal points dividing the jittered points indicates the mean level of poverty for each group.
Now look at the right two “categories,” model_vals and raw_vals. The raw vals are the poverty index itself; there is one horizontal red line for each of the cases shown in the jitterplot. (When you work with students, perhaps you want to trace the red line to the left to show which data point it corresponds to.) If there are multiple cases at the same level of poverty, there will be multiple red lines in the raw vals drawn at that level. Keep that in mind, even though you can’t see it. One red line for every case in the sample.
The model vals are showing the means (or, more generally, the model values). There are different means for None, Several, and Most, so you see three red lines, each at a poverty value corresponding to a group mean. Here too there is one line for the model value of each data point, but since many points have the same model value (for instance, the model value for the None group is about 3.2), the red lines are drawn over one another. The result is that you see only three lines. Again, keep in mind that there is one red line for every case in the sample.
The black bars show the amount of variation from case to case in the model values (left bar) and the raw values (right bar). This is the standard way to measure variation: the standard deviation. It’s the length of the bar that gives the standard deviation. The position doesn’t matter.2
Going back to the controls, notice a checkbox to hide or display the standard deviation bars. Underneath that are the results of some simple calculations. At the very bottom, a button to generate a new sample and the corresponding graphic.
Interpretation and activities
First and foremost, the graphic is a display of data and therefore tells a story about the people in NHANES. To judge from the means, the Poverty index is higher (that is, income is higher) for people in the None category, somewhat lower for people in the Several category, and lower still for the Most category. Perhaps that makes sense. Maybe people are poor because they are depressed. Or maybe it’s the other way around. But most likely poverty and depression are part of a network of linked factors.
All of the statistics are there to help decide whether the data provide compelling evidence for the story. Or, more precisey, do we have good reason to think that the differences among the means are anything more than the play of sampling variability.
An informal way to judge if the differences among the means is statistically demonstrated3 to generate several new samples and observe whether the means show a consistent pattern of differences.
Post = after, hoc = the thing. There is a well known logical fallacy called post hoc ergo propter hoc, which is much beloved by politicians: “After I announced my new program, the stock market went up! My program is good for the economy.” Even though it be a fallacy, post hoc ergo propter hoc can be right in certain situations, particularly those of post hoc comparisons. In statistics, a responsible position is that the post hoc selection of groups to compare is a likely cause of the significance in the difference, so we have to correct for this.↩
Remember that a standard deviation reflects the typical distance of the cases from the mean. That difference is being shown as the length of the bar.↩
I’m using this as a synonym for a common but dangerously ambigous term: “statistically significant.” Demonstrated doesn’t carry the freight of “significant.”↩