
The Little App on resampling and confidence is designed to help you teach about confidence intervals:
- How broad are they and how this depends on the sample size n.
- How it’s possible to use just one sample to get a handle on how much variation there is likely to be if you had collected another sample.
- What set of possibilities the confidence interval covers.
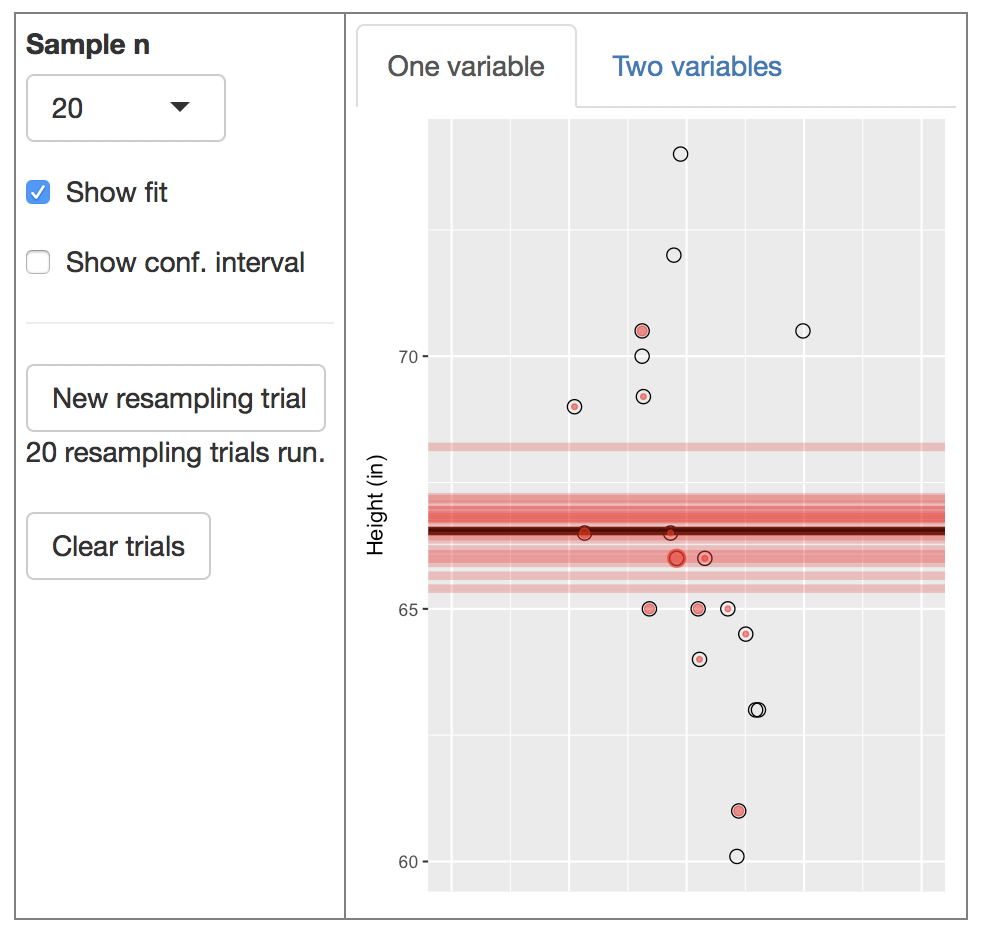
There are two main graphical displays. You specify which one you want to see by selecting one tab or another above the graph.
- The one-variable display shows the distribution of a single variable on the y-axis, with jittering used to prevent overplotting.
- The two-variable display shows a response variable versus an explanatory variable.
The “show fit” checkbox controls whether the model fit to the displayed data is plotted along with the data. For the two-variable display, the model is linear regression. For the one-variable display, the model amounts to the sample mean.
The “show conf. interval” checkbox determines whether or not to show the 95% confidence interval on the mean (for the one-variable display) or the 95% confidence band on the linear model. The confidence interval and band are calculated calculated using normal theory from the single sample being displayed by the black circles.
You can generate a new resampling trial by pressing the button. If the show-fit box is checked, the model fits for all the previous resampling trials will be displayed.
Teaching with the app
What’s resampling?
Start by explaining what resampling is, taking a new sample randomly and with replacement from the cases in the actual sample at hand. Typically, some of the cases in the original sample are never visited in the resample. Correspondingly, some of the original cases appear more than once in the resample.
When you create a new resample, the selected cases are indicated by red dots. Notice that some of the original cases don’t have a red dot; they weren’t selected to be in the resample. Cases that were selected once have a small red dot, cases selected twice have a somewhat bigger dot, and so on; the more times a case appears in the resample, the bigger the dot.
Put up a resample and ask your students to point out cases that are not in the resample and cases that are in the resample multiple times. Do this for both the one- and two-variable displays.
Fitting a model
Check the “show fit” box. In the one-variable plot, the mean of the sample will be shown as a horizontal line. In the two-variable plot, the regression line will be shown.
If you have generated resampling trials, the fit for each of those trials will be shown as well.
Clear the resampling trials to start afresh. Then generate one new resample and its corresponding fit. Point out how the fit for the resample differs from the fit to the original data. (With luck, it will be discernably different. If not, try again.) The reason it’s different is that some of the original cases have been omitted from the resample, and others appear multiple times. And, of course, many of the cases in the original sample appear just once in the resample.
Display resampling variation
Generate many resampling trials. When you have about 20, you may start to see a general pattern in where the fitted models fall with respect to the model fitted to the original sample. Each individual resample is random, but as a group the models fitted to the resamples tend to cluster near the model for the original sample.
How near is “near”? You can see that from the graph in the app. Show how “near” changes for different sample sizes.
Generate 50 to 100 resampling trials. Since there’s a scatter of fitted models, it’s hard to say reliably whether ever future resample will fall into a specified band. But you can eyeball the central band that covers the central 50% of the resamples, or another covering the central 80% of the resamples, or if you had enough trials, the central 95%.
Ask a student to sketch out such a band. Then measure the width of it. (For the two-variable graph, measure the width at the waist of the band, just so that you have an easy to see definition of where the width is to be measured.)
Write down the width and sample size. Do this for several different sample sizes. Point out the \(1/\sqrt{n}\) pattern: as n is larger, the width is smaller.
The confidence interval
The central band that covers 95% of the resamples is called the 95% confidence interval. The interpretation: If you were to generate another resample, there is a 95% chance that it would fall within the confidene interval.
Using resampling is a valid way to generate confidence intervals. For some classes of model – the mean and the regression line are among them – there is also a calculation of the confidence interval based on mathematical theory.
Turn on the theoretical confidence interval. Note that it covers almost all of the resampling trials. The two ways of generating a confidence interval – mathematical theory and resampling – give effectively the same result. It’s a little cleaner graphically to show the theoretical interval.
For instructors
Often, statistics instructors refer to a kind of theoretical interpretation of the confidence interval:
Theoretical interpretation: We have a sample of size n and have calculated some statistical quantities: the sample mean, the slope of a regression line, etc. Now imagine that there is some population that’s practically infinite in size from which we took our sample. We could calculate the same quantities on the whole population. They would presumably be a little different from the results we got with our sample of size n. The confidence interval, when properly constructed, will likely contain the population values. How likely? We can never know if our particular interval contains the population values, but across our careers of calculating many confidence intervals, and the careers of our fellow statistical workers, the 95% confidence intervals will contain the corresponding population quantities about 95% of the time. We can’t be sure, and we can never know, if the particular confidence interval we are calculating now is one of those 95%, but our body of statistical results will average out that way.
This is complex and in many ways unsatisfying. If find it more effective to start with a practical definition and … well … to end with that practical definition as well. We can leave the theoretical interpretation as an exercise in mathematical logic.
Practical interpretation: One of the factors that governs the precision of our statistical results is the randomness introduced by collecting our particular sample instead of some other plausible sample. There are different ways of quantifying how large the effect of this randomness is. One simple way is to model the randomness of sampling by the randomness of resampling. We can operationalize this at any time just by generating a resample from our sample. The 95% confidence interval is the band in which 95% of the resamples we might generate in the future will fall.
What’s important is that the precision typically gets better with larger n — the width of the confidence interval goes as \(1/\sqrt{n}\). Depending on your purpose, you might need high precision or low precision. The confidence interval tells us whether we have the precision we need and, if not, guides us in determining how much data we should collect to have any precision we want.