
Consider this textbook exercise, written in a style that will be familiar to anyone who has taught introductory statistics.1
In late June 2012, Survey USA published results of a survey stating that 56% of the 600 randomly sampled Kansas residents planned to set off fireworks on July 4th. Determine the margin of error for the 56% point estimate using a 95% confidence level.
At some point in the survey process, there was presumably a data table with 600 rows and some variables: the person’s age, sex, county of residence, whether they planned to set off fireworks on July 4, and so on. The problem doesn’t give this data table. And it’s understandable that for the problem at hand a simple summary of the data is adequate: the sample proportion and sample size. The exercise gives \(p_0 = 0.56\) and \(n = 600\).
In StatPREP, we think that the data should be front and center and that statistical methods ought to be taught in a manner that encourages exploration of the data. The LittleApp on proportions does that. The each case in the data is displayed, and students can choose an explanatory variable (or none) as they will.
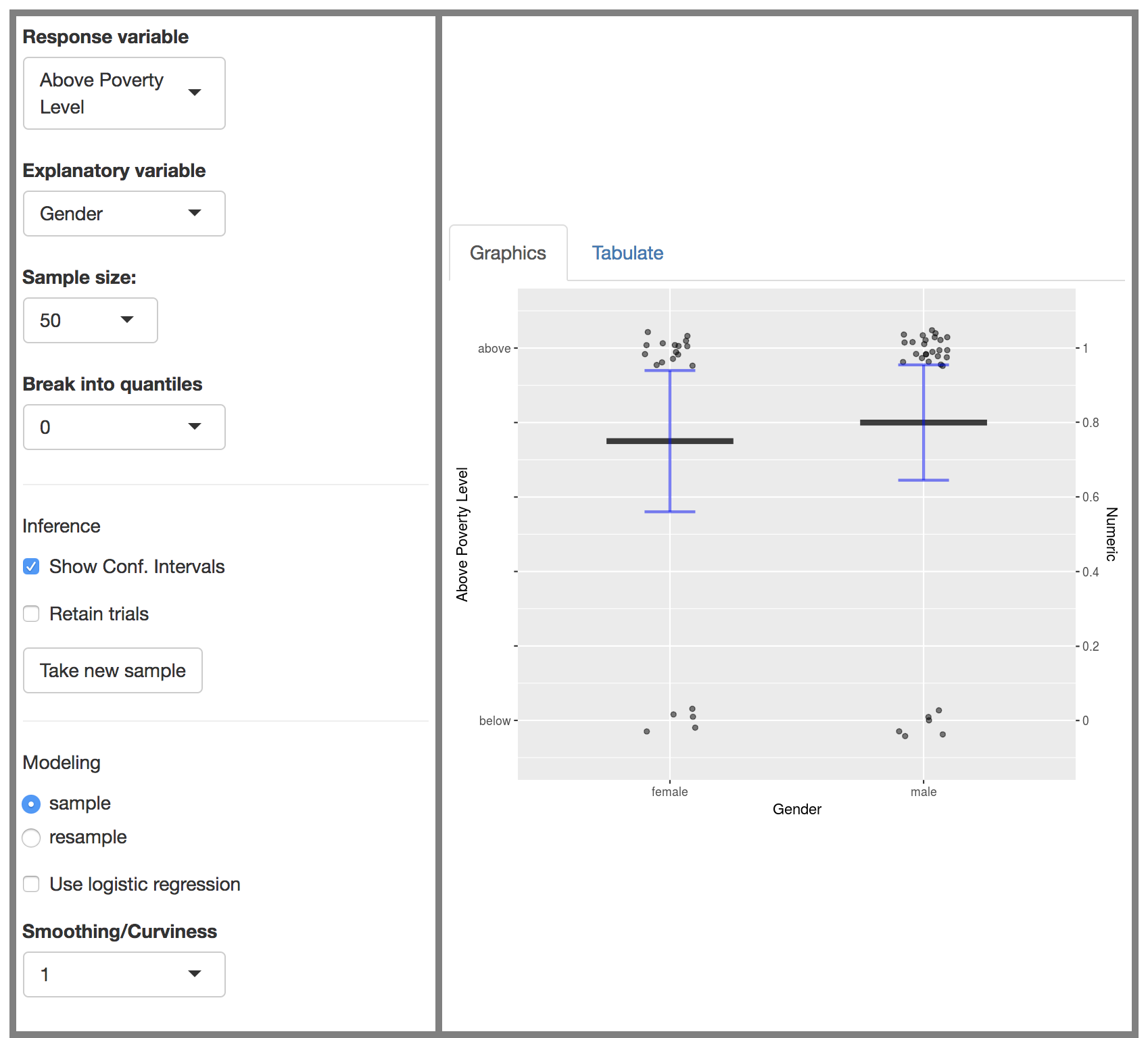
The graphic in the app is a jittered scatter plot. Each case is an individual dot. As with other LittleApps, there is a response variable on the y-axis and an explanatory variable on the x-axis.
I know that this display is unconventional, but there is a good reason even beyond putting data at the center. Something that instructors sometimes lose sight of is the close relationship between the sample proportion \(p_0\) and the mean of a response variable. The sample proportion applies when there are categorical levels in the response variable. When there are two such levels (e.g. set of fireworks or not) they can always be represented as a zero-one quantitative variable. (Note that there is a zero-to-one scale on the right-hand side of the graphic.) That’s more than a trick. Inference on proportions, at least in the way it is usually introduced in textbooks, is the same thing as inference on means.
There are several controls in the app. Fundamental to all uses of the app are the choice of the response variable, the choice of the explanatory variable, and the sample size. The other controls will be described as they are needed for teaching purposes.
The data used in the app is the National Health and Nutrition Survey collection in NHANES. The variable names tell much of what you need to know.
Teaching with the proportions littleapp
We’re going to start with basic levels and then increase in sophistication as we go. For an introductory course, you probably want to make each level its own topic in your course, covering the various topics as the course moves on. For instance, “What’s a proportion?” might be appropriate when you first introduce a proportion, “Confidence intervals” a couple of weeks later, quantitative explanatory variables at the end of the semester.
What’s a proportion?
The app is intentionally set up so that, when started, the explanatory variable is gender. The point is for students to see the same framework throughout the apps: a response and an explanatory variable.
If this is the first jitter plot your students are seeing, explain that the exact position of the point is randomly offset. Each of the points is either at the upper level or the lower level. And each of the points is at a horizontal position corresponding to the group the point is in. (Would it be too pedantic to say, instead of group, “level of the categorical explanatory variable?” Sometimes it’s just not worthwhile to push the technical vocabulary.)
You might want to set the explanatory variable to “none.” This corresponds to the textbook “one proportion.” The x-axis is labelled “none.” The single category on that axis is “All Cases,” which is merely a way to say that the cases are being considered as one, comprehensive group.
Change the sample size to n = 10. Count the number of cases at the upper level. (Watch out! By bad luck, it sometimes happens that two jittered points like on top of one another. You’ll get a hint of this because such points will appear darker than the ones that aren’t overplotted.)
The proportion is, of course, the number of cases at the upper level divided by n. That’s always a number between zero and one. The particular value is indicated by the horizontal line with reference to the numeric scale on the right of the graph.
Up the sample size to 500. Explain that the proportion is still the number of cases at the top level divided by the total \(n\). It’s too tedious to count the points, so we let the computer do it for us.
Leaving the explanatory variable at “none,” try out the different response variables. Do it for n=10 and n=500 (or whatever) so that the students can convince themselves that the proprotion is simply the count at the upper level divided by n. For each different response variable, ask the students to interpret the proportion using phrases like “most people are …” and “about evenly split.”
Discussion question: We generally get somewhat different proportions when we use n=10 or n=500. Why is this? This is a very simple introduction to sampling variability, but you don’t need to call it that yet.
Sampling variation
The set-up is the same as previously.
There are two new controls to introduce. The first is the “Take new sample” button. Each time it is pressed, a new random sample from the entire NHANES data is displayed. Set the sample size to 50 and press the new-sample button many times. The proportion will jump around each time you press.
Now check the “Retain trials” box. This will cause the sample shown in dots to stay put, but will put up the proportion of a new sample each time the new-sample button is pressed. Press it many times. This gives a visual impression of the range of sampling variation.
Note that for small sample sizes, e.g. n=20, the proportion always falls at a discrete level: 0/20, 1/20, 2/20, and so one. This leads to overplotting in the horizontal lines. The dots to the side of the trials let you see how many trials produced each level.
Run sampling trials for large n and for small n. Note that the range of the trials is larger for smaller n.
Using a categorical explanatory variable
Now we’ll use the app with an actual explanatory variable. Pick one that’s categorical, e.g. gender, depressed, home ownership.
For small sample size, go through the counting exercise. You’ll have to count both the top and bottom levels in order to find the proportion for each group.
Try a bunch of different response and explanatory variables. Make sure to interpret the graphs in everyday terms. Does it look like the fraction of people above the poverty level is different for people who own or rent their home? Might it be that poor people can’t afford to buy a home? Or perhaps people who are less settled tend to be renters, and they also are more likely to be poor. Tell a story. Ask the students to tell a story that matches the pattern that they see.
After looking at several combinations of response and categorical explanatory variables, ask the question, “How do we know that this pattern is just an accident of sampling? Might another sample have produced a very different result?” For large and small sample sizes, press the new-sample button many times to get an idea of how much sampling variation there is. Check the retain-trials box so that each sample shows up as new lines in the graph. You can call the collection of lines the sampling distribution. Introduce the (pretty good) rule of thumb: if two levels of the explanatory variable have sampling distributions that have little or no overlap, you can be pretty sure that they data give good reason to think that there is a difference in proportion in the world from which the samples were taken. Sometimes for small n the sampling distributions do overlap while for large n they do not. This tells us that there really is a difference in proportion in the world2 from which the samples were taken, but that with small n we don’t have enough data to justify that conclusion. Collecting samples with large n makes it easier to see a difference if there is one.
Confidence intervals
It’s easy to carry out sampling trials on the computer, but behind the scenes that’s because we already have a large sample from which we’re pulling subsamples. In real work we don’t have this large sample, just the sample at hand that we collected with great expense and labor. Without access to the sampling distribution itself, we need something to stand in for it.
At this point, where you go depends on whether your students have yet seen confidence intervals in any form and whether they’ve seen resampling. Turn on the confidence interval display. One approach is to generate the sampling distribution and show that it’s roughly the same width as the confidence interval. Another is to use resampling instead of sampling. Another is just to say that there is a way to know how precise our estimate of the proportion is.
Show that confidence intervals tend to get smaller as sample sizes get larger.
Quantitative explanatory variables
Some faculty may be unfamiliar with an approach to confidence intervals not grounded in \(p_0\), \(p_1\), \(p_2\), and \(\sqrt{p (1 - p) / n}\). These are part of an apparatus for statistical inference, admittedly one that is commonly found in introductory textbooks, but which is just one of the ways of doing things. A more general framework for statistical inference, regression, subsumes the textbook apparatus and enables us to have much more flexibility in the choice of explanatory variables and the incorporation of covariates.
In particular, regression enables you to use a quantitative variable (e.g. height, age) as an explanatory variable when examining proportions. The proportion indicated at any given level of the explanatory variable (e.g. a height of 170 cm) is more-or-less the proportion we would get if we took out the cases near that level (you can point to which dots are those cases) and calculated the proportion in the usual way: the number at the top level divided by the number at the bottom level.
If you’ve already talked about linear regression, you can be more precise in describing how the line is found: regression of the zero-one response variable against the explanatory variable.
As always, show several different combinations of response and explanatory variable. Some good examples are above poverty level versus height or age, or high-blood pressure versus age or smoking status. Ask the students to interpret the slope of the fitted line in everyday terms: “taller people tend to have more …”, or “there’s no evident relationship between age and …”
And, of course, turn on “retain trials” and show the sampling or resampling distribution at large and small sample sizes. For smaller samples, it can be harder to make a definitive statement about what is the relationship between the response and explanatory variables.
You can turn on the confidence intervals. Any line you can draw that stays within the band of the confidence interval is a plausible match to the data. If there are such lines with different stories, you don’t have enough data to distinguish between the stories: either or neither might hold in the world.
Proportions must be between zero and one.
As you go through various combinations of response and explanatory variables, you will find instances where the confidence interval extends below zero or above one. You’ll also see that when using a quantitative explanatory variable, the line showing proportions might itself go outside the bounds zero to one. This is a mathematical absurdity, since proportions must be between zero and one.
The problem is not in our data but in our methods for calculating confidence intervals and regression models. Using logistic regression solves the problem.
I think it’s unlikely that many instructors will want to teach extensively about logistic regression. And it’s just one of a set of modeling techniques that fall under the name “machine learning.” Some machine-learning methods are mathematically sophisticated (e.g. support vector machines), some are pretty simple (e.g. k-nearest neighbors). Logistic regression is in the middle.
I think it’s reasonable to expect that machine learning will become even more widely used in the modeling and interpretation of data. Here’s a short explanation of logistic regression that is oriented toward instructors with substantial mathematics training. It’s probably not for your students.
- A probability p must fall in the range between zero and one.
- For each value of p, there is a corresponding value p / (1-p). This representation is called an odds. (Odds are routinely used in gambling. They simplify calculating a payout that won’t systematically cause the “house” to lose money.) Odds can range, of course, from zero to \(\infty\).
- Now take the logarithm of the odds, called the log odds. This is a number that can range from \(-\infty\) to \(\infty\).
- In logistic regression, one fits a model whose output is in terms of log odds. Whatever that model might be, translating the log-odds output to a probability will necessarily produce a value between zero and one.
- Fitting a logistic regression model isn’t done with the linear algebraic methods of linear regression. Instead, it is done by systematic search over the model parameter space. Each point in that space generates a probability for each of the cases in the data; put the explanatory variables into the model, calculate the log odds using the given parameters, then translate to probability. The likelihood of the model is the probability of the actual data given the point in parameter space. The model is fit by maximizing this likelihood using numerical optimization.
There’s much more to say about logistic regression and its interpretation. It’s very widely used in clinical research because it enables quantitative covariates to be included in a model in a natural way. (Example: What is the difference in recovery rates for the treatment and placebo groups, taking into account age, sex, blood pressure at entry to the study, …)
This is Exercise 6.7 in the third edition of OpenIntro Statistics, which is available free. See http://openintro/os.↩
Many people call this the “population.” I think students do a little better distinguishing “the world” or “the real world” from the sample itself.↩